How To Structure Terraform Deployments At Scale
Learn to decouple Terraform administration and operations, driving autonomy and standards with the help of Scalr.

Figuring out how to structure your Terraform deployments once you've hit a certain scale is a common issue across the community.
From an administrator's perspective... Do you have a defined way of creating repositories? Do you create a list of approved modules? How do you keep up with what the teams are doing? Do you give engineers autonomy? Do you enforce policy?
From an engineer's perspective... Should I put all resources in a single monolithic deployment? How do I reuse code? Should I break the deployment up into small components or modules? Am I following standards?
To be honest, there isn't a "right" way to do this, but there are a lot of "wrong" ways, it's all situational depending on your use case, and there are a ton of different ways to structure the Terraform deployments at scale. The key is a common framework that can accommodate various workflows and your likely ever changing requirements.
Step #1: Decoupling Terraform administration and operations
As you scale Terraform for your organization, you will need to figure out how to do so in a way that your central DevOps team is not a bottleneck, which means you need to figure out a way to make your developers more autonomous while also reducing blast radius.
To make things easier, at Scalr we've built a flexible hierarchical model that meets the needs of various personas and business requirements. There are two scopes in the hierarchy:
- Account Scope - Think of this as an administrative control plane for your central DevOps team.
- Environment Scope - Think of this as a landing zone, an organizational unit, or similar to a cloud provider account.
If you were to compare this to AWS, the Scalr account would be an AWS master account and the Scalr environments would be similar to the AWS sub accounts where infrastructure is provisioned. The hierarchy makes it very easy for you to centralize the Terraform administration while decentralizing the Terraform operations.
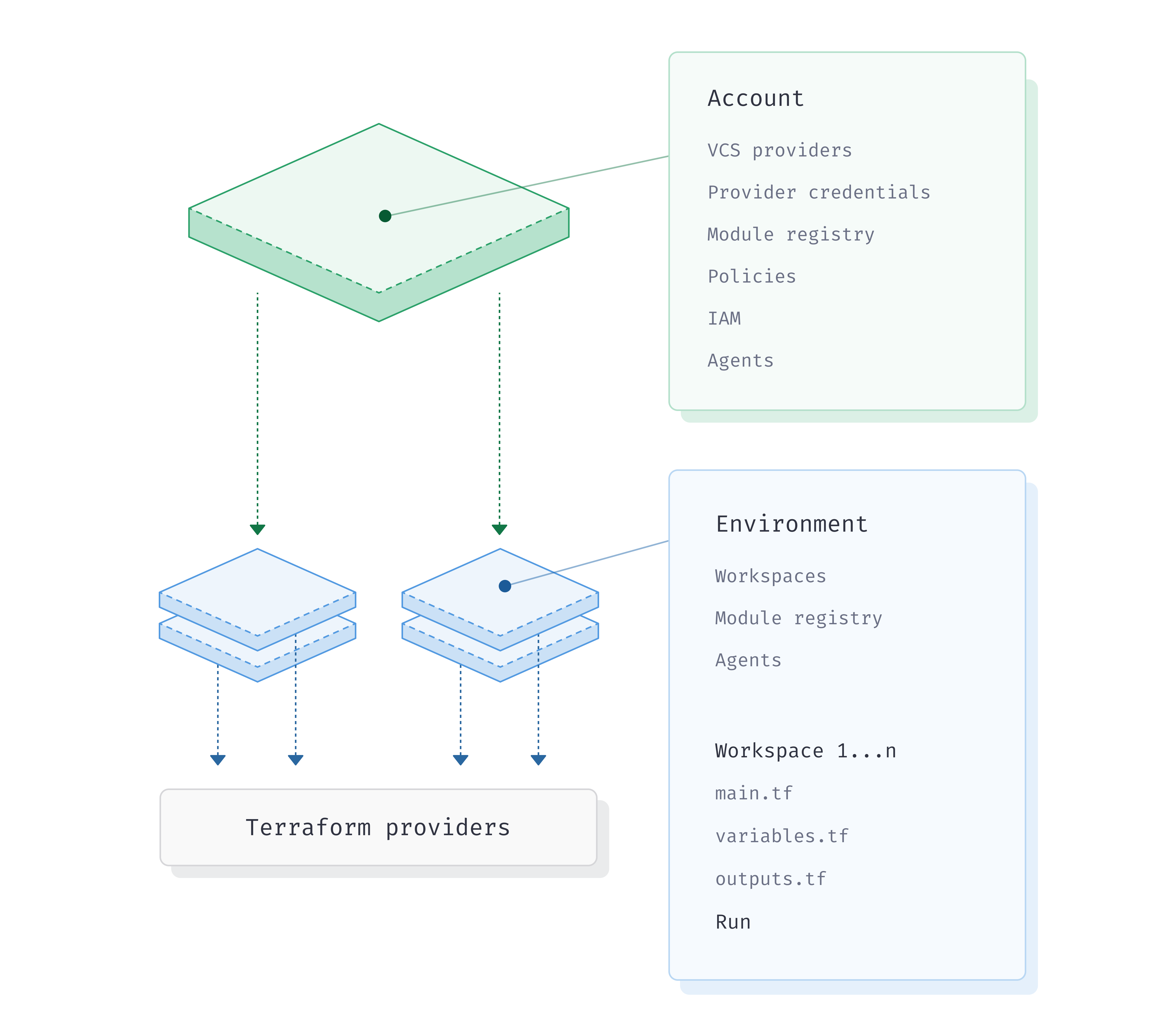
The Scalr hierarchy
Centralizing Terraform administration
The Devops team, who creates and maintains Scalr environments, VCS providers, provider credentials, module registries, OPA policies, teams, and agents would mainly operate at the account scope. All of these objects can be managed from the account scope and assigned/shared with the environments as required (note: the Scalr provider can be used to manage these objects as well). The DevOps team can add any of these objects from the account scope and not have to be concerned about flipping back and forth between contexts to make changes.
On top of managing objects from a single location, the administrator also has operational views across all environments and workspaces in a single dashboard. Observability is invaluable for large scale deployments as seen in the OPA dashboard below:
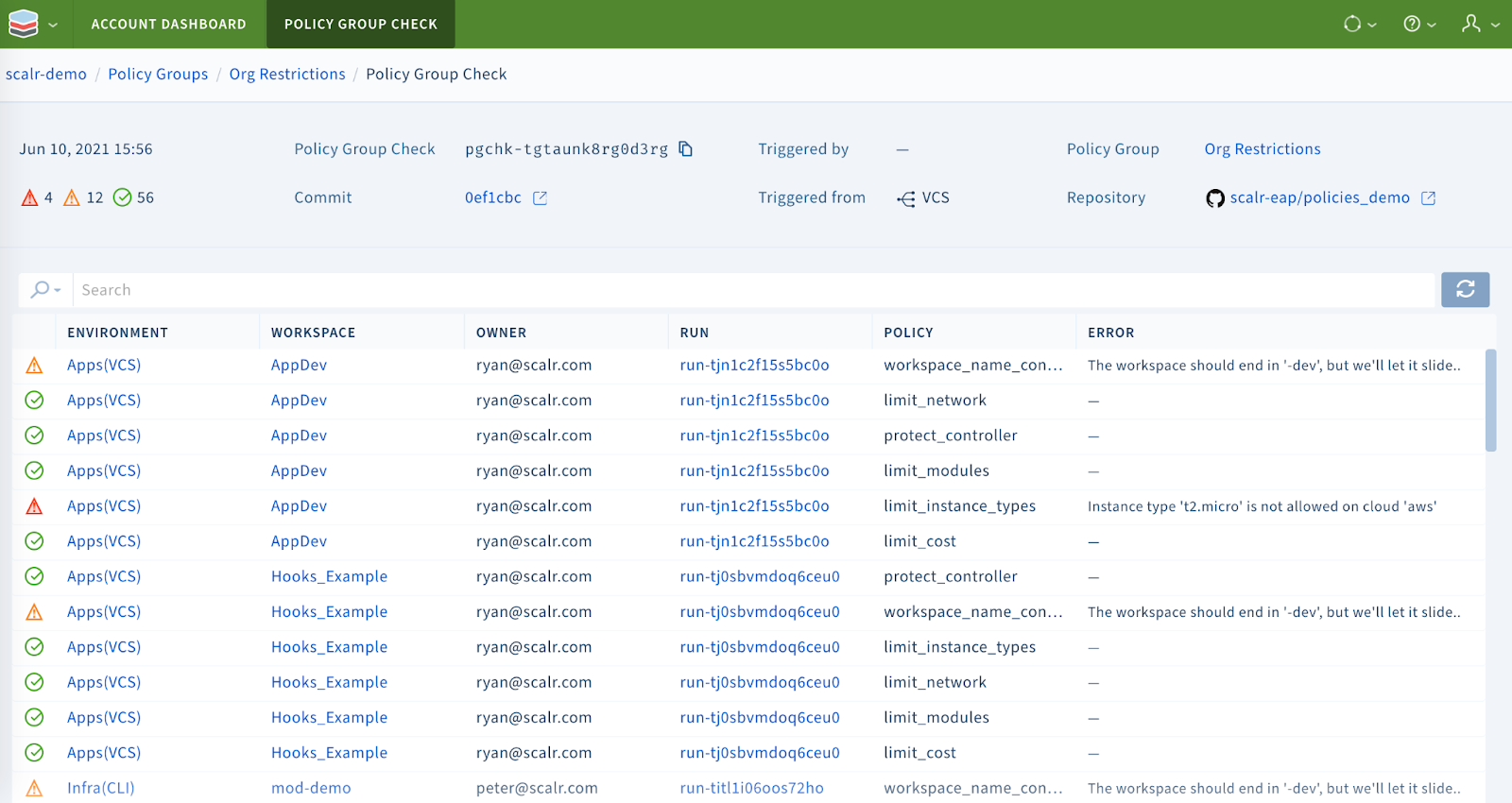
The Open Policy Agent dashboard
In the example, you can see OPA checks across all environments and workspaces from a single dashboard saving the time of having to go into each individual workspace.
You may also want to know which workspaces are consuming the most runs or taking the longest to understand trends among your teams, this can be seen through usage reports:
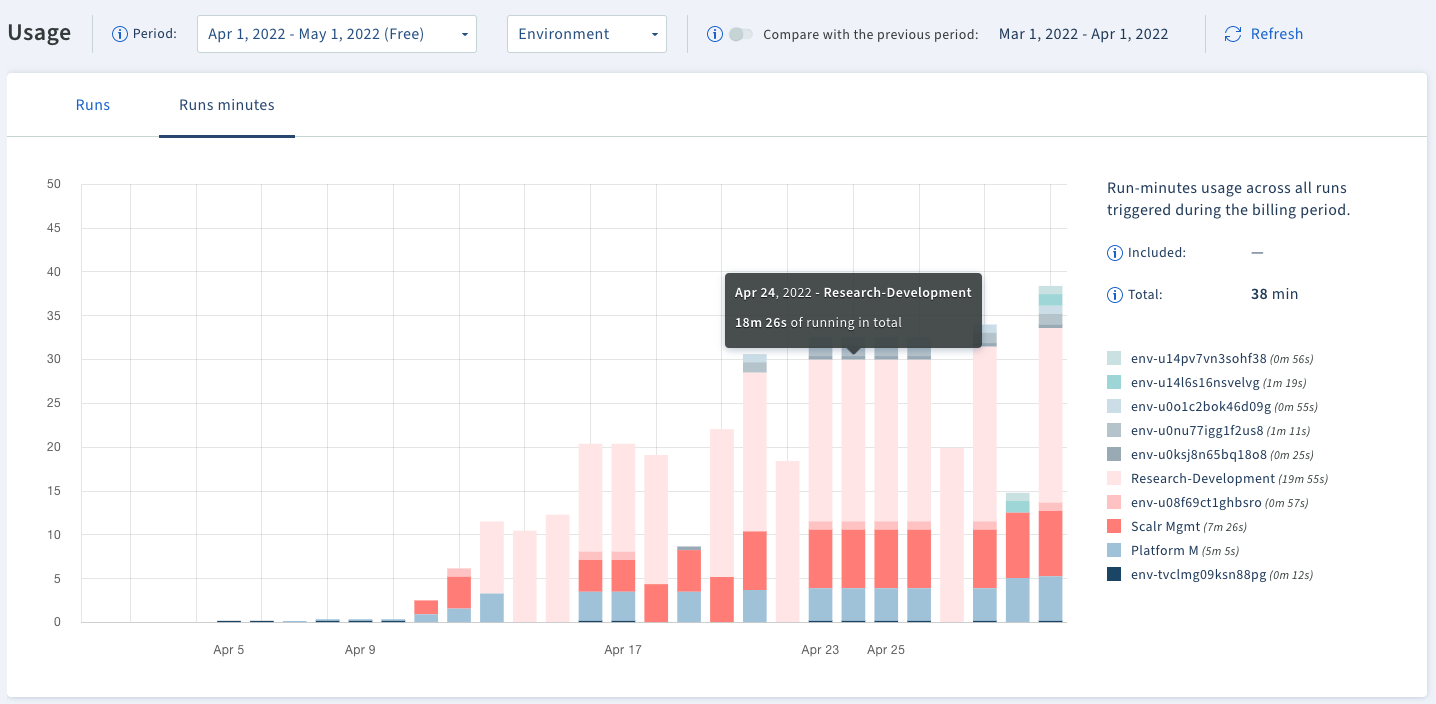
Observe environment/workspace usage
Decentralizing Terraform operations
A Scalr environment is a logical grouping of Terraform workspaces that have a common set of policies, provider credentials, and teams assigned to it. We usually see environments aligned to applications, functions, or cloud accounts. A workspace, the child of an environment, is the result of a Terraform deployment. In the simplest terms, a workspace holds the Terraform state, variables, and run history.
The engineers mainly operate at the environment level where workspaces are created and Terraform runs are executed through their own workflows, whether they are through the Terraform CLI or VCS driven.
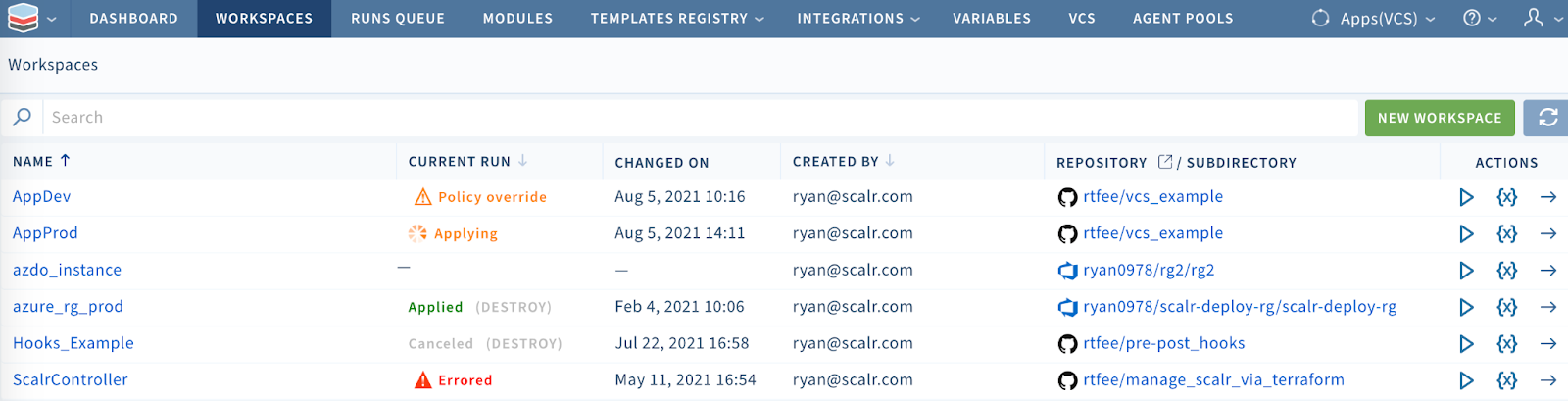
The workspace list
Much like isolated cloud accounts, Scalr environments are isolated areas for teams and users to do their work without interrupting others. All environments and workspaces will inherit objects that were assigned to it from the account scope. A good example of this is setting a variable, like a tag or region, at the environment scope and having all child workspaces automatically inherit it. The engineers within the environment don't have to worry about the standard variables, they are focused on their deployments.
Step #1 takeaway
The Scalr hierarchy makes it very easy to structure your Terraform deployments to ensure engineering teams have isolated environments and the central DevOps team has control and visibility from the account structure. Now that the basics are set, let's see how the structure enables you to reuse your Terraform code.
Step #2: Driving autonomy and standards through reusable code
While there are different opinions on how to structure Terraform, we're convinced that reusable code is the easiest way to standardize modules and scale Terraform. As mentioned in step #1, a hierarchy helps with standardization and autonomy, and the Scalr module registry will help with the reusable code. The Scalr module registry also follows the hierarchical model that was already outlined. A module can be placed at the account or environment scope. If the module is placed at the account scope, it is automatically inherited by all environments and can be used by any workspace. If a module is placed at the environment scope, only workspaces within that environment can use the module. This model allows engineers to easily view and consume approved modules. The module registry is straightforward, so the question then becomes, how do you approach Scalr environments to enable the reuse of code?
Following your cloud provider model
As we mentioned earlier, environments can be structured many ways, but for most customers, it makes sense to follow the same tenancy model that you use in your cloud providers. The majority of our customers have cloud accounts/subscriptions that equate to a group, an app, etc. If this concept works for you in the cloud, then it's perfectly acceptable to set up Scalr environments the same way. By breaking out environments this way, you are reducing the blast radius of changes and you can ensure that proper policies are placed on non-prod and prod environments. You can also manage and vend environments through the Scalr Terraform provider just like you would with any other cloud provider.
Next, you will need to figure out what a workspace means to you. This is more objective, but we have seen an increasing trend to have more workspaces with less amount of resources allowing for quick deployments and easy troubleshooting. The code in the workspaces will point to your modules from the registry with the only thing changing per workspace being the variable file(s) resulting in reusable code.
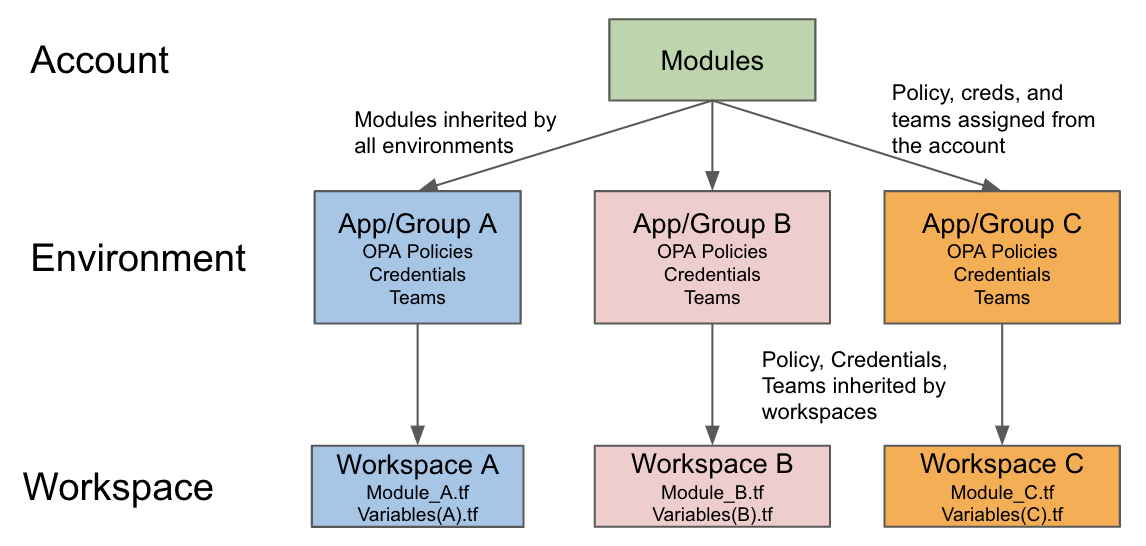
Each app and its environment has a dedicated Scalr environment
In the example above each group has their own Scalr environment to deploy their Terraform workspaces. Each Scalr environment automatically inherits modules, credentials, OPA policies, and variables depending on who the group is. If the standard modules from the account scope are being used, the team can then inject their own additional variables directly into the workspace configuration to reuse the code. They also have complete autonomy over their environment and workspaces, resulting in decentralization of the Terraform operations.
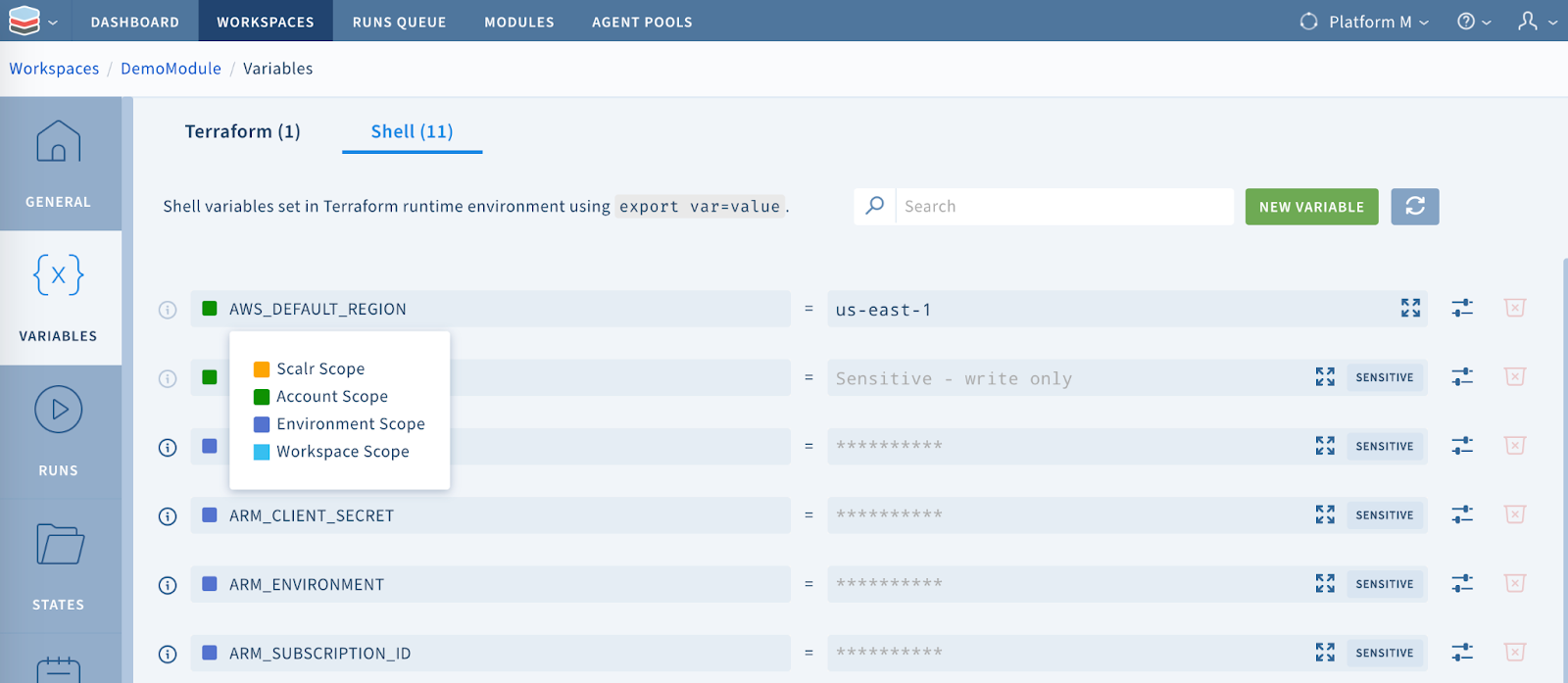
Variables in the workspace are automatically inherited from the account scope
Step #2 takeaway
The Scalr account and environment structure is extremely useful in helping isolate your teams, while not increasing operational overhead. Equally important, with the module registry following the multi-tiered approach the central DevOps now has a framework to promote code reuse and increase autonomy among the engineering teams.
Summary
There are a ton of different ways that Terraform deployments can be automated, standardized, and structured, but the key is making sure you have modules set up in a way that makes them easy to consume and reusable. The Scalr hierarchy does exactly that for any size organization due to the inheritance model as well as the administrative control plane.

