
.webp)
.webp)
.webp)
Your costs = usage. Period.

Operating Terraform at scale is not an easy task. As a platform team, there are many components that need to be monitored to ensure your developers can work in an autonomous way to maximize their efficiency. Some questions to ask yourself as you start scaling your Terraform usage:
All of these questions revolve around reporting and visibility. If you can answer all of these in a matter of seconds, then you're likely going to have smooth operations.

I generally break this down into three areas: Operational Dashboards for the pipeline, reporting for current and historical information, and monitoring which will catch things you weren’t able to see in the operations dashboard or reporting.
In terms of operations, you want to be able to view how the Terraform runs are processing, but most importantly, from a single place. Rather than wasting time jumping from workspace to workspace, it’s important to see the current runs in the context in which you are working.
If you’re the owner of a specific application and operating within that environment, then you’ll want to see only the runs for that environment.
If you're managing a platform that developers use for Terraform operations, then you’ll want to see all of the runs across all environments and workspaces. That is where the Scalr run dashboards help.
The time this saves when searching for runs, assisting in an incident, or prioritizing runs is not trivial.
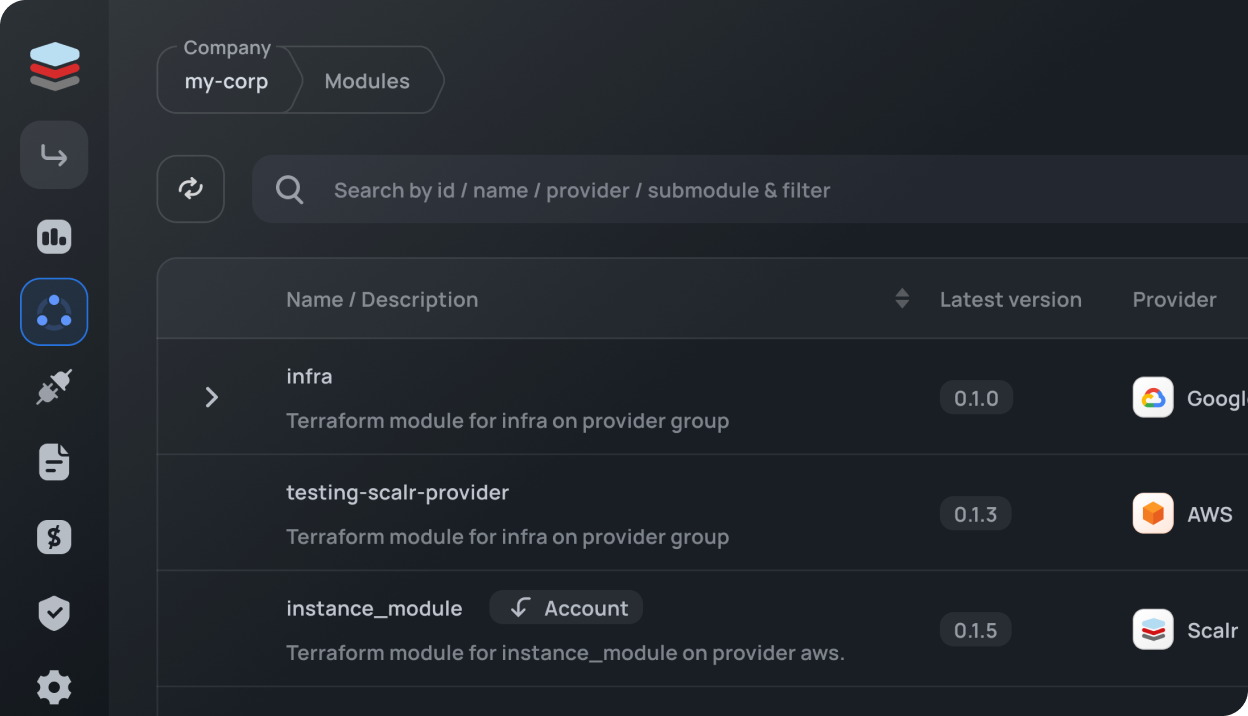
Now that you have a view into the current operations, you also need an understanding of the usage of modules, providers, and Terraform versions. Having an understanding of this will help avoid technical debt allowing you to focus energy on developing rather than maintaining.
Can you easily determine which Terraform versions, modules, or providers are used across your Terraform ecosystem? Do you know what source the developers are pulling modules or providers from? If the answer is no, then your organization is not likely operating at maximum efficiency.
By having this information readily available you will be able to ensure you’re spending your time in areas that are most impactful to the business.
Now that you have operational dashboards in place and reports to give you a grade on how well your Terraform platform is being maintained, you’ll need to figure out how to identify issues in the pipeline that are not obvious. By streaming Terraform run events to a tool like Datadog you will be able to quickly understand system wide issues or build alerts to watch for run errors in some of the more critical workspaces.
As you grow you’ll also want to understand how the pipeline is keeping up with the demand. This can be seen in the run dashboards, but assuming you are not watching this all day, you will want to be alerted of a queue backing up due to a lack of resources. Using Scalr to stream events into Datadog will not only allow you to alert on Terraform workspace level issues, but you're overall pipeline.
Adopting Terraform is not hard, but scaling it is. As you continue to adopt, keep in mind the main three components to assist with scaling:
By doing this from the start, you will be able to point out issues or incidents that might have gone unseen in the past ensuring your team is operating at maximum efficiency.
